From: http://www.theguardian.com/public-leaders-network/2014/apr/15/big-data-open-data-transform-government
Both types of data can transform the world, but when government turns big data into open data it's especially powerful
Joel Gurin, New York University
Guardian Professional, Tuesday 15 April 2014 10.49 BST
Big data and the new phenomenon open data are closely related but they're not the same. Open data brings a perspective that can make big data more useful, more democratic, and less threatening.
While big data is defined by size, open data is defined by its use. Big data is the term used to describe very large, complex, rapidly-changing datasets. But those judgments are subjective and dependent on technology: today's big data may not seem so big in a few years when data analysis and computing technology improve.
Open data is accessible public data that people, companies, and organisations can use to launch new ventures, analyse patterns and trends, make data-driven decisions, and solve complex problems. All definitions of open data include two basic features: the data must be publicly available for anyone to use, and it must be licensed in a way that allows for its reuse. Open data should also be relatively easy to use, although there are gradations of "openness". And there's general agreement that open data should be available free of charge or at minimal cost.
The relationship between big data and open data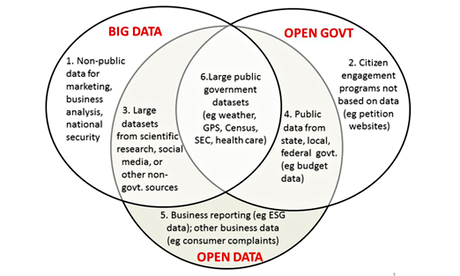
Source: Joel Gurin
This Venn diagram maps the relationship between big data and open data, and how they relate to the broad concept of open government.
More....







